Search is one of the biggest pieces of the puzzle when building a composable solution with Sitecore’s XM Cloud. Sitecore offers their own product, Sitecore Search, and there are a couple other search vendors that have native connectors. But what if you need to set up a search product that does not have a native connector to Sitecore, such as Yext? In this post, we’ll discuss how to use GraphQL + Experience Edge to crawl Sitecore via Yext’s API connector.
The first thing we want to do is figure out how we’ll get out content out of Sitecore. Ideally we want to be able to do this with a single query, rather than chaining queries together, in order to simplify the process of setting up the API crawler in Yext. For this, we’ll use a GraphQL search query. Let’s take a look at an example query:
query YextSiteCrawl(
$numResults: Int
$after: String
$rootItem: String!
$hasLayout: String!
$noIndex: Int
) {
search(
where: {
AND: [
{ name: "_path", value: $rootItem, operator: EQ }
{ name: "_hasLayout", value: $hasLayout }
{ name: "noIndex", value: $noIndex, operator: NEQ }
]
}
first: $numResults
after: $after
) {
total
pageInfo {
endCursor
hasNext
}
results {
id
name
path
url {
path
url
}
fields {
name
jsonValue
}
}
}
}Let’s take a look at this query, starting with the search filters.
- _path allows us to query for every item that contains the rootPath in its path. For our site crawler, we’ll want to pass in the GUID of the site’s home page here.
- _hasLayout is a system field. This filter will exclude items that do not have a presenation assigned to them, such as folders and component datasources. We’ll want to pass in “true” here.
- noIndex is a custom field we have defined on our page templates. If this box is checked, we want to exclude it from the crawl. We’ll pass in “1” here.
- numResults controls how many results we’ll get back from the query. We’ll use 10 to start, but you can increase this if you want your crawl to go faster. (Be wary of the query response size limits!)
- after is our page cursor. In our response, we’ll get back a string that points to the next page of results.
In the results area, we’re asking for some system fields like ID, name, path, and url. These are essential for identifying the content in Yext. After that, we’re asking for every field on the item. You may want to tune this to query just the fields you need to index, but for now we’ll grab everything for simplicity’s sake.
A question you may be asking is, “Why so many parameters?” The answer is to work around a limitation with GraphQL for Experience Edge:
Due to a known issue in the Experience Edge GraphQL schema, you must not mix literal and variable notation in your query input. If you use any variables in your GraphQL query, you must replace all literals with variables.
https://doc.sitecore.com/xp/en/developers/hd/21/sitecore-headless-development/limitations-and-restrictions-of-experience-edge-for-xm.html
The only parameter we want to pass here is “after”, which is the page cursor. We’ll need our crawler to be able to page through the results. Unfortunately, that means we have to pass every literal value we need as a parameter.
Let’s look at the result of this query:
{
"data": {
"search": {
"total": 51,
"pageInfo": {
"endCursor": "eyJzZWFythycnRlciI6WzE3MDE2OTQ5MDgwMDAsIjYwMzlGQTJE4rs3gRjVCOEFCRDk1AD5gN0VBIiwiNjAzOUZBMkQ5QzIyNDZGNUI4QUJEOTU3NURBRkI3RUEiXSwiY291bnQiOjF9",
"hasNext": true
},
"results": [
{
"id": "00000000000000000000000000000000",
"name": "Normal Page",
"path": "/sitecore/content/MyProject/MySite/Home/Normal Page",
"url": {
"path": "/Normal-Page",
"url": "https://xmc-myProject-etc-etc.sitecorecloud.io/en/Normal-Page"
},
"fields": [
{
"name": "title",
"jsonValue": {
"value": "Normal Page title"
}
},
{
"name": "summary",
"jsonValue": {
"value": "Normal Summary"
}
},
{
"name": "noIndex",
"jsonValue": {
"value": false
}
},
{
"name": "topics",
"jsonValue": [
{
"id": "00000000-0000-0000-0000-000000000000",
"url": "/Data/Taxonomies/Topics/Retirement",
"name": "Retirement",
"displayName": "Retirement",
"fields": {}
},
{
"id": "00000000-0000-0000-0000-000000000000",
"url": "/Data/Taxonomies/Topics/Money",
"name": "Money",
"displayName": "Money",
"fields": {}
}
]
}
]
}
...
]
}
}
}In the results block we have our pages, along with all the fields we defined on the page template in the fields block. In the pageInfo block, we have endCursor, which is the string we’ll use to page the results in our crawler.
The next step is to set up the crawler in Yext. From Yext, you’ll want to add a “Pull from API” connector. On API Settings page, we can configure the crawler to hit Experience Edge in the Request URL field, pass our API key in the Authentication section, then put our GraphQL request in the Request Body section. Finally, we can set up the Pagination Control with our cursor. Easy, right?
Unfortunately, we’ll hit a problem here. Yext (as of this writing) only supports passing pagination parameters as query parameters. When we’re using GraphQL, we need to pass variables as part of the request body in the variables block. To work around this limitation, we’ll need to wrap our query in a simple API.
Next.js makes creating an API easy. You drop your api into the /pages/api folder and that’s it! Let’s make a simple API wrapper to take our page cursor as a query parameter and then invoke this query on Experience Edge. We’ll call our api file yextCrawl.ts.
import type { NextApiRequest, NextApiResponse } from 'next'
type ResponseData = {
message: string
}
export default async function handler(
req: NextApiRequest,
res: NextApiResponse<ResponseData>
) {
try {
if (!req) {
return;
}
const cursor = req.query['cursor'];
const crawlQuery = `
query YextSiteCrawl(
$numResults: Int
$after: String
$rootItem: String!
$hasLayout: String!
$noIndex: Int
) {
search(
where: {
AND: [
{ name: "_path", value: $rootItem, operator: EQ }
{ name: "_hasLayout", value: $hasLayout }
{ name: "noIndex", value: $noIndex, operator: NEQ }
]
}
first: $numResults
after: $after
) {
total
pageInfo {
endCursor
hasNext
}
results {
id
name
path
url {
path
url
}
fields {
name
jsonValue
}
}
}
}
`;
const headers = {
'content-type': 'application/json',
'sc_apikey': process.env.YOUR_API_KEY ?? ''
};
const requestBody = {
query: crawlQuery,
variables: {
"numResults" : 10,
"after" : cursor ?? "",
"rootItem": "{00000000-0000-0000-0000-000000000000}",
"hasLayout": "true",
"noIndex": 1
}
};
const options = {
method: 'POST',
headers,
body: JSON.stringify(requestBody)
};
const response = await (await fetch('https://edge.sitecorecloud.io/api/graphql/v1', options)).json();
res.status(200).json(response?.data);
}
catch (err) {
console.log('Error during fetch:', err);
}
};Let’s walk through this code.
We’re making a simple handler taking in a NextRequest and a NextResponse. We’ll check the request for our cursor parameter, if it exists. The GraphQL query we have as a literal string, cut and pasted from the XM Cloud playground where we tested it. The API key gets passed in the header, and we’ve configured this in our env.local and as an environment variable in Vercel.
Our request body will contain the query and the variables. This is where we’ll get around the limitation in the Yext Pull from API crawler. We’ll set up the cursor we pulled from the query parameters here. Our other variables we pass to the query are hard coded for the sake of this example.
Finally we use fetch to query Experience Edge and return the response. The result should be the same JSON we got from testing our query in the playground earlier. Once we deploy this api to Vercel, we can see it working at: https://my-nextjs-project.vercel.app/api/yextCrawl
Try hitting that url and see if you get back your Sitecore content. Then grab the endCursor value and hit it again, passing that value as the cursor parameter in the query string. You should see the next page of results.
Back in Yext, we’ll set up our Pull from API connector again, this time hitting our Vercel hosted API wrapper.
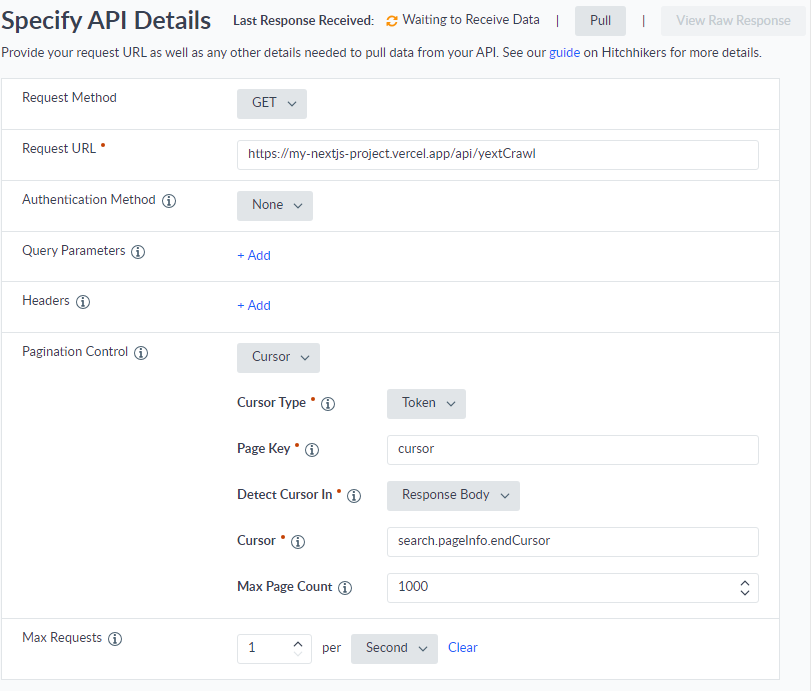
As you can see this is a lot easier to configure! Note the values of our cursor parameter under Pagination Control. These correspond to the cursor query parameter we defined in our wrapper API, and the endCursor data in the json response from our GraphQL query. It’s also important to configure the Max Requests setting. We’re limiting this crawler to 1 request per second so we don’t hit the request limit in Experience Edge.
You can test the connector with the Pull button on the top right. If you’ve set up everything correctly, you should see the View Raw Results button light up and be able to see your results in a modal window.
From here, you can configure the mappings of your Sitecore fields to your Yext entities. That is out of the scope of this post, but Yext’s documentation will help you there. One suggestion I will make is to map the Yext entity’s ID to the page’s Sitecore GUID, defined as id in our crawler query response.
Once it’s all set, save your connector, then you can run your crawler from the connector’s page by clicking “Run Connector”. If you’ve set everything up correctly, you should see your Sitecore content flowing into your Yext tenant.