
This post is part of a series of posts on setting up your Sitecore application to run with Solr Cloud. We’ll be covering the procedure for setting up a Sitecore environment using the Solr search provider, and the creation of a 3-node Solr cloud cluster. This series is broken into four parts.
- Part 1 – Architecture
- Part 2 – Setting Up Zookeeper and Solr
- Part 3 – Creating Your Sitecore Collection
- Part 4 – Tuning Solr for Production
For the first part of this series, we’ll go over some assumptions, prerequisites, definitions, as well as the architecture of Solr Cloud and how it interacts with a Sitecore application.
Prerequisites
The steps discussed in these posts were tested with Sitecore 7.2 update 3, Solr 4.9.1, and Zookeeper 3.4.6. In addition to the core software, I used a few other tools to get everything set up. You’ll need 7-zip to extract the tar.gz packages. I used NSSM to set up the Zookeeper and Solr services on the individual server nodes. Finally, to simulate load-balancing requests to the Solr Cloud nodes, I used the Application Request Routing and URL Rewrite IIS modules.
This series also assumes you’re familiar with setting up a single instance of Sitecore with Solr as the search provider. If you’ve never done this before, Dan Solovay’s blog post describes the process of switching the default Lucene search provider for the Solr search provider.
Solr Cloud
It’s important to understand what Solr Cloud is and how it works in order to have the proper architecture in place. From the Apache wiki,
SolrCloud is designed to provide a highly available, fault tolerant environment for distributing your indexed content and query requests across multiple servers. It’s a system in which data is organized into multiple pieces, or shards, that can be hosted on multiple machines, with replicas providing redundancy for both scalability and fault tolerance, and a ZooKeeper server that helps manage the overall structure so that both indexing and search requests can be routed properly.
Solr Cloud allows you to split your index into shards and to create replicas of these shards. The shards and their replicas are distributed among the individual nodes. Zookeeper manages the distribution of documents and requests to these nodes.
Architecture
To create a functioning Solr Cloud, you’ll need at least 2 running instances of Solr and a Zookeeper to manage them. These Solr nodes would contain an index with a single shard, replicated across both nodes. Such a configuration would look like this:

However, this configuration creates a single point of failure, the Zookeeper, and therefore is not ideal for a truly fault tolerant architecture. Instead collection of Zookeepers should be used, referred to as a Zookeeper Ensemble.
Zookeeper requires a quorum to resolve requests, meaning at least 1/2 the zookeepers +1 in the ensemble must agree. A Zookeeper ensemble of at least 3 instances is required to reach a quorum. This ensemble could tolerate the failure of one instance and still function.
It’s recommended that Zookeeper and Solr run on separate servers. However, many organizations are constrained on the number of servers they can procure. Since Zookeeper does not consume much of the server resources, it can safely co-exist with Solr. In this case it is recommended that Solr have its own dedicated disk. Such a configuration would look like this:
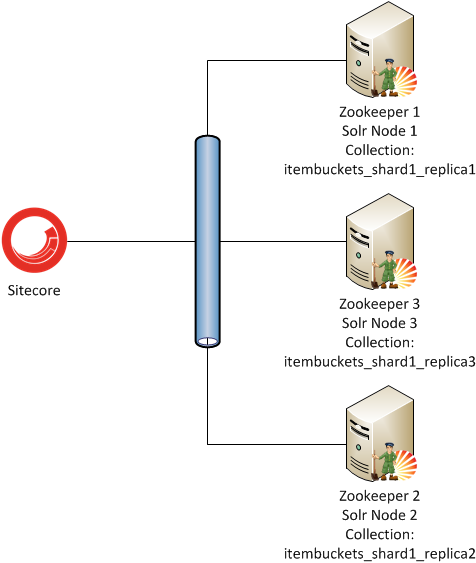
Solr Cloud and Sitecore
Sitecore’s search provider layer depends on Solr.NET, which currently does not support the querying syntax you’d normally use to make requests to Solr Cloud. Requests from your Sitecore application to Solr Cloud need to be routed through a load balancer, as depicted in the diagram above. The load balancer will distribute requests among the Zookeepers, which in turn hand them off to the individual nodes. Configuring this will be discussed in Part 3 of this series.